
当我们在感叹ChatGPT的妙语连珠时,你是否好奇过:究竟是什么样的“心脏”,在支撑这些超级AI没日没夜地思考?答案不是你熟悉的CPU,也不仅仅是显卡GPU,而是一位更专注、更硬核的“特种兵”——TPU(Tensor Processing Unit)。
今天,作为国产可重构TPU芯片的先行者,万协通将带你剥开晦涩的技术外壳,看懂这块决定AI未来的核心硬件,以及中国芯片如何换道超车,上演一场精彩的“变形记”。
AI时代的“偏科生”——读懂TPU
在芯片的大家族里,如果说CPU是总指挥官:擅长规划,不擅长搬砖;GPU是施工大队:能承接各类任务却受限于固定作业流程;那么TPU就是特种机甲:专用、适合、极速。
1. 为什么AI不爱用CPU?
CPU内部拥有极其复杂的控制单元(Control Unit),擅长逻辑调度和统筹规划,但负责具体计算的ALU(算术逻辑单元)占比并不高。它就像一位“统领全局的总指挥官”,运筹帷幄决胜千里,但如果让他亲自去处理AI模型里成千上万个繁琐的加减乘除,效率极低。
2. GPU不仅仅是用来打游戏的
GPU虽然堆叠了成千上万个SM(流式多核处理器)单元,就像一支“全能的装修大队”,人多力量大,什么活都能干。但它依然受限于传统的冯诺依曼架构,SM单元需要频繁访问内存,如果没有大内存支撑,经常会因为内存带宽不足(“缺料”)而停工等待。
3. TPU:为AI而生的“数学天才”
万协通可重构TPU芯片采用了创新的可重复应用的BOU(基本运算单元)架构。这些BOU就像是可灵活组装的特种装备,专门针对AI张量运算进行了极致优化。它不再是通用的工具,而是“为AI量身定制的特种机甲”。通过BOU的灵活重构,应对各种数据的运算时畅通无阻,实现了极致的专用性与速度。一句话总结,可重构TPU芯片专精于一件事:矩阵运算。
撞上“内存墙”——传统架构的困境
传统的芯片架构(冯·诺依曼架构)发展至今仍保留着一个致命伤:“计算”和“存储”是分家的。
想象一下,一位顶级大厨在炒菜,但他的冰箱却在三公里外。
每炒一道菜,大厨都得停下来,开车去冰箱拿一颗葱;
切完了,再开车去放回刀;
炒完了,再开车把盘子运回冰箱。
这就是芯片界著名的内存墙问题。在传统AI芯片中,90%的功耗和时间其实都浪费在了“运送数据”的路上,而不是真正的“计算”上。 这导致了高昂的电费、巨大的发热量和难以降低的成本。
万协通的破局——做芯片界的“乐高大师”
面对这一行业痛点,万协通没有选择盲目堆砌硬件,而是秉持着高效利用,持续优化的理念,提出了一套革命性的解决方案。
万协通的思路很简单:既然数据在内存与计算单元间反复搬运太慢,那我们就重构数据通路,让数据在计算单元间直接“接力”流转,不再反复进出内存,彻底打破“内存墙”的阻隔。 [延伸]


图1:不同芯片架构特性与定位对比
万协通自研了独有的可重构TPU架构。在他们的芯片里,不再是静态的电路,而是由无数个基本运算单元(BOU,Basic Operation Unit) 组成的动态可配置电路。
这些BOU就像是乐高积木:
当AI模型需要做“卷积”运算时,软件一声令下,积木瞬间拼成“卷积机”;
下一秒需要做“全连接”运算时,它们自动拆散,重构成“乘法器”。
这种“软件定义硬件”的能力,让芯片具有了生命力。它不再是被动地跑程序,而是根据程序的需求,主动改变自己的物理结构,达成100%的算力利用率。
为了打破“内存墙”,万协通设计了流水线(Pipeline)数据并行架构。
数据一旦进入芯片,就像上了流水线。上一级BOU算完,直接扔给下一级,中间绝不回写到内存。消灭了无效的数据搬运,功耗大幅降低,计算效率成倍提升。
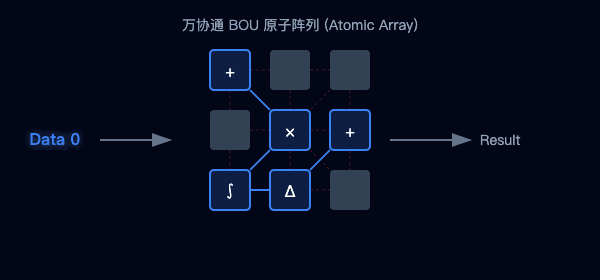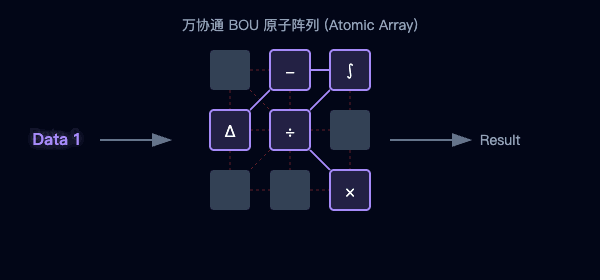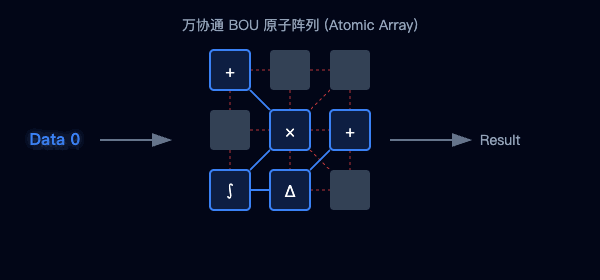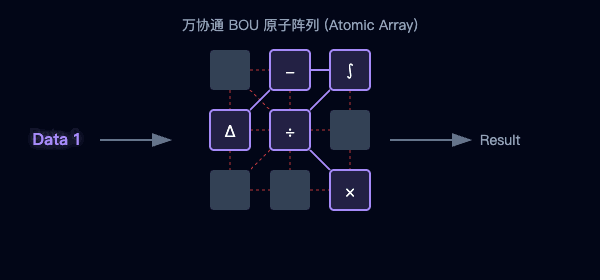
图2:传统架构的数据往返(左)与万协通的并行流水线(右)对比
如果你关注国产芯片,一定听说过“CUDA生态壁垒”。很多国产芯片之所以难用,是因为不仅要造硬件,还要去适配成千上万个复杂的软件“算子”。
万协通做了一件“釜底抽薪”的事。
他们发现,无论AI算法多么花哨,拆解到底层,都是线性多项式运算。
因此,万协通的可重构TPU芯片不需要庞大的算子库,当遇到新模型时,编译器直接指挥BOU这些“原子”现场搭建。
这意味着:万协通的芯片天生具有极强的适应性,无需漫长的软件适配周期,拿来就能用。
【原子重构,万象随心】
万协通并非单纯的芯片制造者,而是底层计算架构的深度重构者。公司的核心技术特征在于对基础运算单元(BOU)原子性与可塑性的极致挖掘。正是基于这一“底层重构”基因,万协通打造了革命性的可重构TPU芯片——它能根据AI模型的需求,通过配置动态重组BOU这些“算力原子”,以流水线并行架构彻底打破传统芯片的“内存墙”桎梏,实现了硬件架构对上层算法的完美适配与高效支撑。
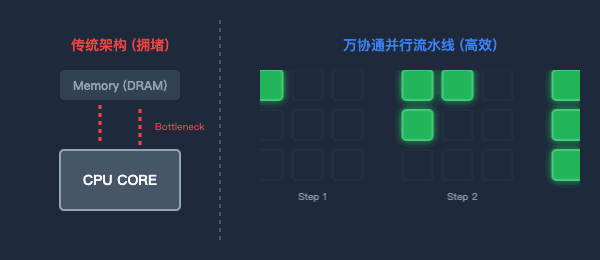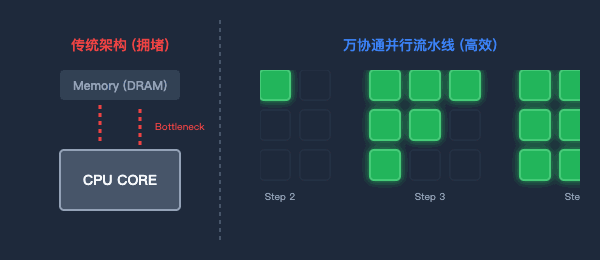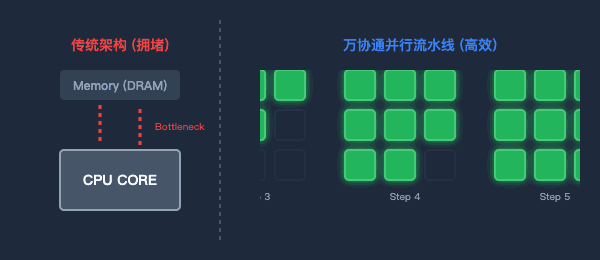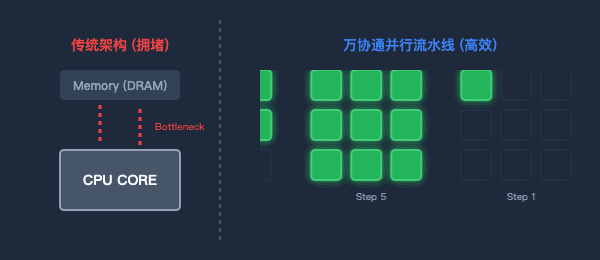
图3:海量BOU原子阵列—聚沙成塔,按需重组
【降本增效的实干家】
在这个算力贵如油的时代,万协通通过去掉昂贵的Cache(缓存)堆叠,利用可重构架构,实现了:
更小的芯片面积 = 更低的制造成本
更高的能效比 = 更省电的运行成本
这将让高性能AI算力不再是巨头的专利,让更多的中小企业、边缘计算设备也能拥有“超级大脑”。
在摩尔定律逐渐失效的今天,算力的提升不能再只靠死磕纳米制程。万协通的可重构TPU向世界证明:架构的创新,同样能带来指数级的性能飞跃。
作为国产可重构TPU芯片的先行者,万协通不仅是在造一颗芯片,更是在探索一种让硬件追随软件、让算力像水一样自由流动的全新范式。在这场关乎国运的算力竞赛中,万协通正带着中国芯的智慧,突围而出,重构未来。
免责声明
本站转载的文章,版权归原作者所有;旨在传递信息,不代表本站的观点和立场。不对内容真实性负责,仅供用户参考之用,不构成任何投资、使用等行为的建议。如果发现有问题,请联系我们处理。
本站提供的草稿箱预览链接仅用于内容创作者内部测试及协作沟通,不构成正式发布内容。预览链接包含的图文、数据等内容均为未定稿版本,可能存在错误、遗漏或临时性修改,用户不得将其作为决策依据或对外传播。
因预览链接内容不准确、失效或第三方不当使用导致的直接或间接损失(包括但不限于数据错误、商业风险、法律纠纷等),本网站不承担赔偿责任。用户通过预览链接访问第三方资源(如嵌入的图片、外链等),需自行承担相关风险,本网站不对其安全性、合法性负责。
禁止将预览链接用于商业推广、侵权传播或违反公序良俗的行为,违者需自行承担法律责任。如发现预览链接内容涉及侵权或违规,用户应立即停止使用并通过网站指定渠道提交删除请求。
本声明受中华人民共和国法律管辖,争议解决以本网站所在地法院为管辖法院。本网站保留修改免责声明的权利,修改后的声明将同步更新至预览链接页面,用户继续使用即视为接受新条款。